推荐一下多方案的应用(包含 Android、iOS、桌面端、 Web 应用)渠道统计与深度链接服务平台 catinstall ,如果你想直接自部署或使用托管服务可以试试 https://catinstall.com
技术实现方案
- 数据匹配方案
目前其实有很多平台能够对接了,这一块目前已经是一个技术市场了,价格也有便宜有贵,其实整套技术要实现并不难,关键是能不能拿下几个技术点:1. (精准匹配)实现 Web 端和原生端(Android or IOS)用户拥有相同的唯一识别码(跨浏览器指纹),用于识别用户从哪个网页来的。 2.(模糊匹配)通过 Web 端收集用户 IP,浏览器 UA,浏览器指纹等数据,用户进入 APP 之后也收集这些数据继续一个模糊匹配(需要一个比较好数据模糊匹配的算法) 上面两种的话就是目前市面这些平台上主流的做法,思路也是比较成熟。思路很简单,可是关键技术确实需要时间攻破。下面就是他们公开的流程图
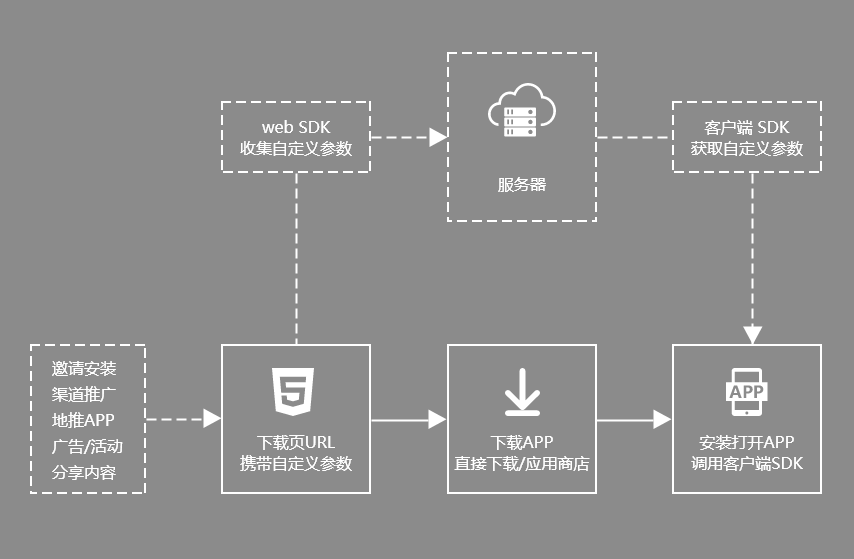
花了一天时间折腾了跨浏览器指纹,发现最大的问题是不同设备上表现不一样,我自己的一台小米手机是能够有部分浏览器指纹生成出来是跨浏览器也表现一致的。但是我试了一台华为发现生成出来的浏览器指纹数据完全没有规律(可能华为的用户数据安全还是要强很多吧)。 目前来说要想走数据匹配这个方案的话应该只能试试模糊匹配了(后面我会讲到我对于这部分的一个实现想法)。
- APK 添加描述方案
除了上面讲到的通过服务器进行数据匹配来实现之外,在一个技术群里有大佬还给了我一个比较现实的实现方案。通过改变 APK 的描述(实际上 APK 就是一个打上了签名的 ZIP,所以可以直接给 APK 弄上压缩包描述)实现嵌入数据(其实我之前也有想到这个方案,但是我一直认为破坏 APK 之后需要重新签名,这样实现效率较低而且对安装包侵入较大),结果大佬的实验发现压缩包描述是被写入到了文件尾,这样并不会破坏 APK 签名。实验结果如下图
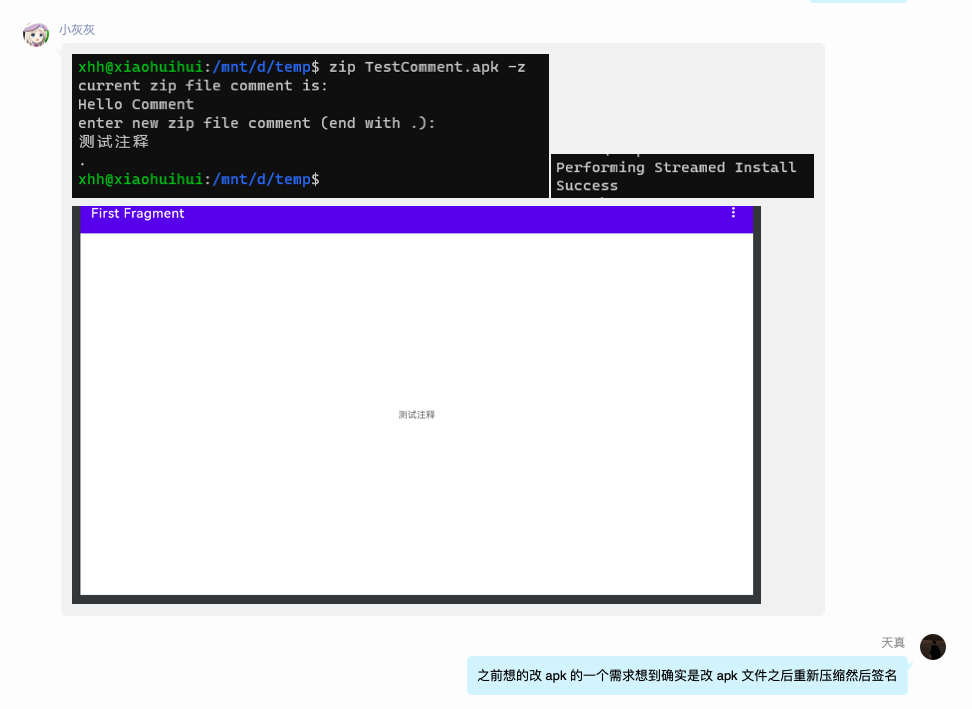

大佬们给的具体实现流程是通过请求下载时服务器端给 APK 打上指定的数据标识,然后安装 APK 之后读取标识走业务逻辑就好了。 确实,针对 Android 的话这一个方案已经很漂亮了,可是也有一定的限制,首先下载之前对文件的处理或多或少也还是对服务器带来了一些负载压力。然后就是相对还是对软件有些侵入的处理。感觉用于邀请这种场景还是有些“大材小用”了,不过可以用于那种地推渠道包的生成或者那种生成一个包让别人去推广作为一个特殊的标识安装包还是非常实用的。
- 本地 Http Server 轮询方案
还有一种就是用户打开网页之后,网页开启轮询一个本地 Http Server API。用户第一次安装 APP 之后会开启一个 Http Server 就可以接收到网页那边轮询请求传递过来的数据了。(参考 QQ web 端获取电脑上已登陆账号可以直接授权登陆技术) 这个方案的缺点很明显,那就是不稳定,可能会出现用户安装 app 时关闭了浏览器,浏览器进程被系统关闭等…
模糊数据匹配方案的设想
大家先看看这篇文章 https://paper.seebug.org/350/ 实现模糊匹配流程:
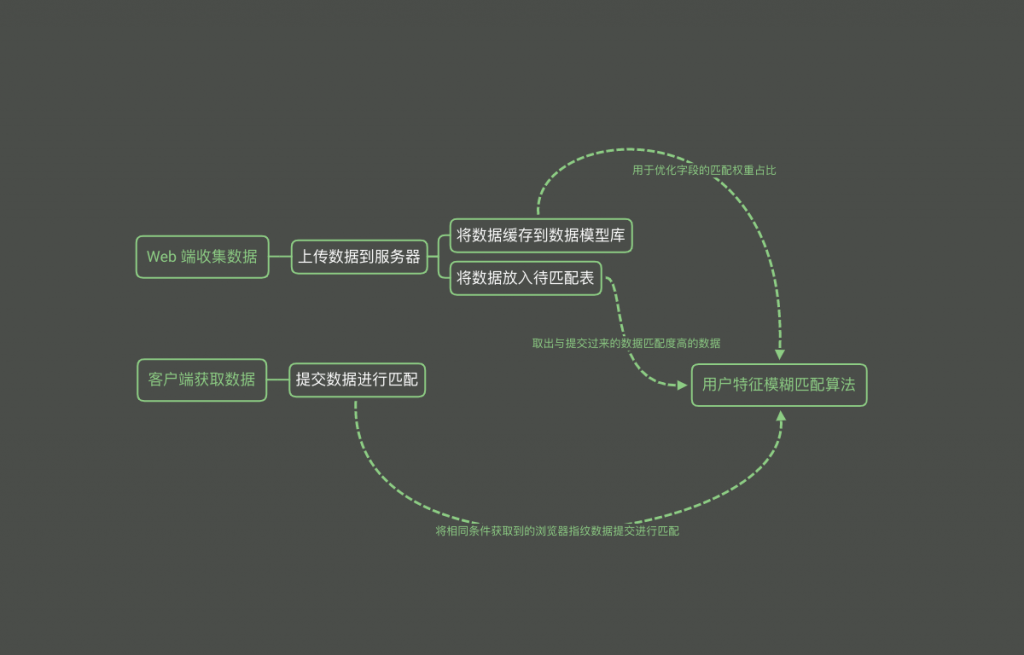
整个流程中首当其冲的就是两端的数据收集,那我们必须明白我们需要收集什么样的数据。 由于整个流程是从浏览器开始的,所以我们肯定是要想办法让客户端方面向浏览器端靠齐的,所以我们客户端中的数据也是利用 WebView 组件来收集。这样的话整个数据来源就统一了,那么这样就够了吗?不,就算是全部都是通过浏览器来收集数据也会遇到不同 Tab 之间的数据会有部分差异,浏览器之间收集到的数据差异就更大了。当然现在如果是一个浏览器中的话已经有比较好的解决方案 fingerprintjs(GitHub:https://github.com/fingerprintjs/fingerprintjs/) 了 但是我们就是需要跨 APP 同步数据呀,所以就涉及到了跨浏览器指纹(说实在的这个技术的话还是蛮基础的,可能完整的学术名应该叫: 用户身份识别与行为追踪,大量用于互联网的盈利大头广告行业和大数据杀熟等领域… 当然那些算法的复杂度和数据量都不是我们这个小玩意能比的) 好了现在我们看看我们能通过浏览器取到那些数据吧。 普通设备信息(操作系统、分辨率、像素比等…) 请求头数据( IP、Cookie、UA …) 浏览器指纹(audio 指纹、canvas 指纹、webgl 指纹) 以上就是我们目前能通过常规手段能拿到的用户特征数据,这其中有很多数据是没有特征性的或者说特征性比较小,还有很多数据根本就没有任何固定特征,所以我们需要先清洗一波数据,知道对我们有用的数据和他们的一个重复率(我们可以通过数据重复率来取出这个特征的权重),上面博客的作者已经帮我们弄到一张初步统计过的数据表了,我们前期可以通过参考这个来确定参与模糊匹配的数据特征和每个特征初始的权重
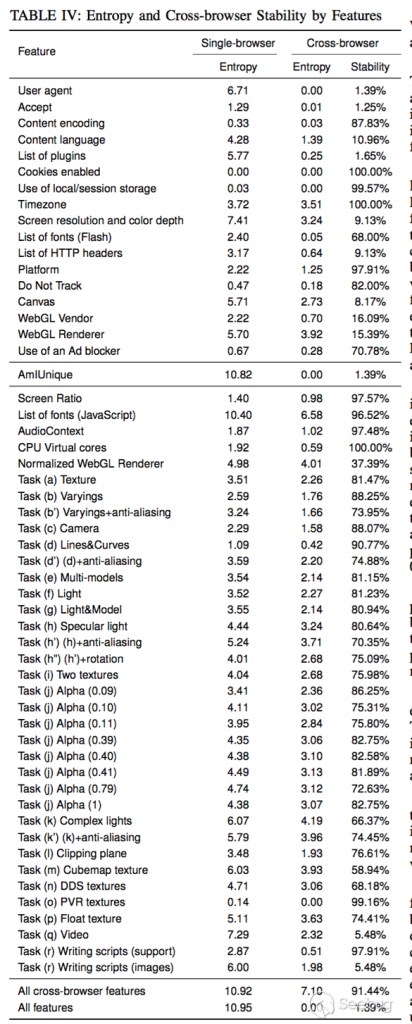
现在我们确定好数据了,现在本来应该是直接动手写算法了的,但是我目前技术好像有点不知该如何下手。所以我只能在这里讲一下我的一些想法,希望能够抛砖引玉。 首先在 Web 端采集到的数据分为两份,一份直接缓存起来(用于数据分析),然后将一份放入待匹配列表(待匹配列表中的数据超过设定时间自动会销毁) 用户那边打开 APP 之后采集到客户端的数据提交上来之后,将数据拆分首先匹配权重高的,如 IP 、audio 指纹、canvas 指纹、webgl 指纹这种重复率不高的数据,匹配上的话就直接将相关数据通知回调回去,匹配不上的话就开始根据其他数据解析逐项匹配算出最终的匹配率(设定一个最低匹配率,低于这个匹配率的话就匹配失败),每一特征数据项都有需要有一个匹配率的占比权重(因为不同特征数据项的重复率是不一样的),那缓存的数据有什么用呢?其实是用于后续的数据分析和优化的,因为设备不断的迭代更新特征数据项的重复率也会发生一些改变,是可以实现一下根据数据样本自动细调特征数据项的权重使其更加准确。
参考资料
(Cross-)Browser Fingerprinting via OS and Hardware Level Features
GitHub - AJLoveChina/fingerprintDemo: 浏览器指纹 audio指纹,webgl指纹,canvas指纹的生成算法
GitHub - fingerprintjs/fingerprintjs: Browser fingerprinting library with the highest accuracy and s
基于二维码识别的安卓系统手机软件下载方法用于实现用户行为追踪的方法、设备、浏览器及电子设备
GitHub - Urinx/browspy: 浏览器用户全部信息收集js
特别鸣谢(排名不分前后)
@小灰灰
@xkeyC
@何言
@QQ小冰
@仙客

问题来了,IOS怎么解决这个问题呢
ios 可以参考一下通过浏览器指纹匹配的方式
多方案的 Android、iOS、桌面端、 Web 应用渠道统计与深度链接服务平台 https://catinstall.com