使用 Node JS 处理 docx 文档
最近想用 js 搞搞 docx 文档的处理,其实 docx 文档也是属于一个压缩包,我们解压看看里面的结构吧
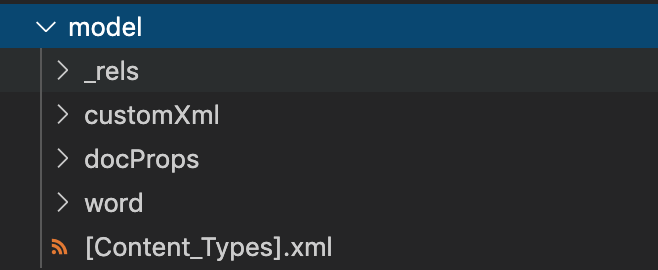
解压 docx 文档后我们大概能得到一个这样的结构包含这些目录和组件:
[Content_Types].xml:这个文件描述的是整个文档内容的类型,把各个xml文件组合成一个整体。
docProps 文件夹:这个文件夹中的xml记录了docx文档的主要属性信息,Core.xml:描述文件的创建时间,标题,主题和作者等给予open xml约定文档格式的通用文件属性,App.xml:描述文档的其他属性,文档类型,版本,只读信息,共享,安全属性等特定的文件属性
rels 文件夹:这个文件夹存放了所有指定的rels文件
rels 文件:这些文件描述了文档结构中的起始关系,也可以叫做关系部件
word 文件夹:这个文件夹基本就包含了一些样式和文档内容了,我们这里也只操作这里面的 document.xml 内容文件
我这里只是简单描述了一下,如果想了解更多可以上维基百科看看相关文章:https://en.wikipedia.org/wiki/Office_Open_XML
我们看看怎么用 JavaScript 解压我们的 Docx 吧,解压文件夹使用 unzip2 模块
var fs = require('fs');
const unzip = require('unzip2')
fs.createReadStream(__dirname + '/test.docx')
.pipe(unzip.Extract({ path: __dirname + '/test' }));解压成功之后我们就可以解析 xml 了,这里用 xml2js 模块,我这里写了一篇博客讲过怎么用 xml2js 的有兴趣的可以去看看 https://bin.zmide.com/?p=494
var xml2js = require("xml2js");
var parseString = xml2js.parseString;
var fs = require("fs");
var xml = fs.readFileSync(__dirname + '/test/document.xml', "utf-8");
parseString(xml, function(err, result) {
const xmlDocsRootNode = result["w:document"]["w:body"][0]["w:p"];
// ... 处理文档实现处 ...
});这里我贴一下我的处理实现吧(因为文档内容不同可能获取的 key 不同,这里仅供参考)
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<w:document xmlns:wpc="http://schemas.microsoft.com/office/word/2010/wordprocessingCanvas" xmlns:mc="http://schemas.openxmlformats.org/markup-compatibility/2006" xmlns:o="urn:schemas-microsoft-com:office:office" xmlns:r="http://schemas.openxmlformats.org/officeDocument/2006/relationships" xmlns:m="http://schemas.openxmlformats.org/officeDocument/2006/math" xmlns:v="urn:schemas-microsoft-com:vml" xmlns:wp14="http://schemas.microsoft.com/office/word/2010/wordprocessingDrawing" xmlns:wp="http://schemas.openxmlformats.org/drawingml/2006/wordprocessingDrawing" xmlns:w="http://schemas.openxmlformats.org/wordprocessingml/2006/main" xmlns:w14="http://schemas.microsoft.com/office/word/2010/wordml" xmlns:w10="urn:schemas-microsoft-com:office:word" xmlns:w15="http://schemas.microsoft.com/office/word/2012/wordml" xmlns:wpg="http://schemas.microsoft.com/office/word/2010/wordprocessingGroup" xmlns:wpi="http://schemas.microsoft.com/office/word/2010/wordprocessingInk" xmlns:wne="http://schemas.microsoft.com/office/word/2006/wordml" xmlns:wps="http://schemas.microsoft.com/office/word/2010/wordprocessingShape" xmlns:wpsCustomData="http://www.wps.cn/officeDocument/2013/wpsCustomData" mc:Ignorable="w14 w15 wp14"><w:body><w:p><w:pPr><w:keepNext w:val="0"/><w:keepLines w:val="0"/><w:pageBreakBefore w:val="0"/><w:widowControl w:val="0"/><w:kinsoku/><w:wordWrap/><w:overflowPunct/><w:topLinePunct w:val="0"/><w:autoSpaceDE/><w:autoSpaceDN/><w:bidi w:val="0"/><w:adjustRightInd/><w:snapToGrid/><w:spacing w:line="240" w:lineRule="atLeast"/><w:ind w:firstLine="640"/><w:jc w:val="center"/><w:textAlignment w:val="auto"/><w:outlineLvl w:val="9"/><w:rPr><w:rFonts w:ascii="华文中宋" w:hAnsi="华文中宋" w:eastAsia="华文中宋"/><w:sz w:val="32"/><w:szCs w:val="32"/></w:rPr></w:pPr><w:r><w:rPr><w:rFonts w:hint="eastAsia" w:ascii="华文中宋" w:hAnsi="华文中宋" w:eastAsia="华文中宋"/><w:sz w:val="32"/><w:szCs w:val="32"/></w:rPr><w:t>xxxx</w:t></w:r><w:r><w:rPr><w:rFonts w:hint="eastAsia" w:ascii="华文中宋" w:hAnsi="华文中宋" w:eastAsia="华文中宋"/><w:sz w:val="32"/><w:szCs w:val="32"/></w:rPr><w:t>这是一个deom</w:t></w:r><w:commentRangeStart w:id="0"/><w:r><w:rPr><w:rFonts w:hint="eastAsia" w:ascii="华文中宋" w:hAnsi="华文中宋" w:eastAsia="华文中宋"/><w:sz w:val="32"/><w:szCs w:val="32"/></w:rPr><w:t>demo</w:t></w:r></w:p><w:p><w:pPr><w:keepNext w:val="0"/><w:keepLines w:val="0"/><w:pageBreakBefore w:val="0"/><w:widowControl w:val="0"/><w:kinsoku/><w:wordWrap/><w:overflowPunct/><w:topLinePunct w:val="0"/><w:autoSpaceDE/><w:autoSpaceDN/><w:bidi w:val="0"/><w:adjustRightInd/><w:snapToGrid/><w:spacing w:line="240" w:lineRule="atLeast"/><w:ind w:firstLine="640"/><w:jc w:val="center"/><w:textAlignment w:val="auto"/><w:outlineLvl w:val="9"/><w:rPr><w:rFonts w:ascii="华文中宋" w:hAnsi="华文中宋" w:eastAsia="华文中宋"/><w:sz w:val="32"/><w:szCs w:val="32"/></w:rPr></w:pPr><w:r><w:rPr><w:rFonts w:hint="eastAsia" w:ascii="华文中宋" w:hAnsi="华文中宋" w:eastAsia="华文中宋"/><w:sz w:val="32"/><w:szCs w:val="32"/></w:rPr><w:t>[文档:xxxx</w:t></w:r><w:r><w:rPr><w:rFonts w:hint="eastAsia" w:ascii="华文中宋" w:hAnsi="华文中宋" w:eastAsia="华文中宋"/><w:sz w:val="32"/><w:szCs w:val="32"/></w:rPr><w:t>] V1.0</w:t></w:r><w:commentRangeEnd w:id="0"/><w:r><w:rPr><w:rStyle w:val="7"/><w:sz w:val="32"/><w:szCs w:val="32"/></w:rPr><w:commentReference w:id="0"/></w:r></w:p><w:p><w:pPr><w:keepNext w:val="0"/><w:keepLines w:val="0"/><w:pageBreakBefore w:val="0"/><w:widowControl w:val="0"/><w:kinsoku/><w:wordWrap/><w:overflowPunct/><w:topLinePunct w:val="0"/><w:autoSpaceDE/><w:autoSpaceDN/><w:bidi w:val="0"/><w:adjustRightInd/><w:snapToGrid/><w:spacing w:line="240" w:lineRule="atLeast"/><w:ind w:firstLine="640"/><w:jc w:val="center"/><w:textAlignment w:val="auto"/><w:outlineLvl w:val="9"/><w:rPr><w:rFonts w:ascii="华文中宋" w:hAnsi="华文中宋" w:eastAsia="华文中宋"/><w:sz w:val="32"/><w:szCs w:val="32"/></w:rPr></w:pPr><w:r><w:rPr><w:rFonts w:ascii="华文中宋" w:hAnsi="华文中宋" w:eastAsia="华文中宋"/><w:sz w:val="32"/><w:szCs w:val="32"/></w:rPr><w:t>this is APP</w:t></w:r></w:p><w:p><w:pPr><w:keepNext w:val="0"/><w:keepLines w:val="0"/><w:pageBreakBefore w:val="0"/><w:widowControl w:val="0"/><w:kinsoku/><w:wordWrap/><w:overflowPunct/><w:topLinePunct w:val="0"/><w:autoSpaceDE/><w:autoSpaceDN/><w:bidi w:val="0"/><w:adjustRightInd/><w:snapToGrid/><w:spacing w:line="240" w:lineRule="atLeast"/><w:textAlignment w:val="auto"/><w:outlineLvl w:val="9"/><w:rPr><w:rFonts w:hint="eastAsia"/></w:rPr></w:pPr></w:p><w:p><w:pPr><w:keepNext w:val="0"/><w:keepLines w:val="0"/><w:pageBreakBefore w:val="0"/><w:widowControl w:val="0"/><w:kinsoku/><w:wordWrap/><w:overflowPunct/><w:topLinePunct w:val="0"/><w:autoSpaceDE/><w:autoSpaceDN/><w:bidi w:val="0"/><w:adjustRightInd/><w:snapToGrid/><w:spacing w:line="240" w:lineRule="atLeast"/><w:textAlignment w:val="auto"/><w:outlineLvl w:val="9"/><w:rPr><w:rFonts w:hint="eastAsia"/></w:rPr></w:pPr><w:r><w:rPr><w:rFonts w:hint="eastAsia"/></w:rPr><w:t>import React, { Component, useContext, useCallback, useEffect, useMemo } from 'react';</w:t></w:r></w:p><w:p><w:pPr><w:keepNext w:val="0"/><w:keepLines w:val="0"/><w:pageBreakBefore w:val="0"/><w:widowControl w:val="0"/><w:kinsoku/><w:wordWrap/><w:overflowPunct/><w:topLinePunct w:val="0"/><w:autoSpaceDE/><w:autoSpaceDN/><w:bidi w:val="0"/><w:adjustRightInd/><w:snapToGrid/><w:spacing w:line="240" w:lineRule="atLeast"/><w:textAlignment w:val="auto"/><w:outlineLvl w:val="9"/></w:pPr><w:bookmarkStart w:id="0" w:name="_GoBack"/><w:bookmarkEnd w:id="0"/></w:p><w:sectPr><w:headerReference r:id="rId5" w:type="default"/><w:pgSz w:w="11900" w:h="16840"/><w:pgMar w:top="1440" w:right="1800" w:bottom="1440" w:left="1800" w:header="851" w:footer="992" w:gutter="0"/><w:cols w:space="425" w:num="1"/><w:docGrid w:type="lines" w:linePitch="312" w:charSpace="0"/></w:sectPr></w:body></w:document>
// -------------------------------------
// 上面是我的 document.xml 文件内容,下面是解析处理代码,这里是向文档的最后一行插入一行 Hello world
// -------------------------------------
const xmlDocsRootNode = result["w:document"]["w:body"][0]["w:p"];
const xmlDocsNode = result["w:document"]["w:body"][0]["w:p"][4];
let newXmlDocsNode = ObjCopy(xmlDocsNode);
newXmlDocsNode["w:r"][0]["w:t"][0] = "Hello world";
let xmlButton = xmlDocsRootNode[xmlDocsRootNode.length - 1];
xmlDocsRootNode[xmlDocsRootNode.length - 1] = newXmlDocsNode;
xmlDocsRootNode[xmlDocsRootNode.length] = xmlButton;通过 xml2js 解析后会返回一个 JSON 对象这边直接处理相关对象就好了
这里我再加一个辅助函数,JavaScript 深度克隆对象函数,因为我处理的时候要插入文本内容,就需要深度克隆一个对象(避免改变值的时候把原来的内容也改变了)
function ObjCopy(target) {
let copyed_objs = [];
// 此数组解决了循环引用和相同引用的问题,它存放已经递归到的目标对象
function _deepCopy(target) {
if (typeof target !== "object" || !target) {
return target;
}
for (let i = 0; i < copyed_objs.length; i++) {
if (copyed_objs[i].target === target) {
return copyed_objs[i].copyTarget;
}
}
let obj = {};
if (Array.isArray(target)) {
obj = [];
// 处理target是数组的情况
}
copyed_objs.push({ target: target, copyTarget: obj });
Object.keys(target).forEach(key => {
if (obj[key]) {
return;
}
obj[key] = _deepCopy(target[key]);
});
return obj;
}
return _deepCopy(target);
}处理过后还是 JSON 对象,我们怎么把它转回 xml 并且保存呢?
var fs = require("fs");
var xml2js = require("xml2js");
var builder = new xml2js.Builder({
renderOpts: { pretty: false, indent: " ", newline: "" }
});
var xmlTest = builder.buildObject({ ...result });
fs.writeFile(__dirname + '/test/document.xml', xmlTest, function(err) {
if (err) {
return console.error(err);
}
// console.log("数据写入成功!");
});好了,现在我们的 Docx 文档基本处理完成了,就差最后一步打包了
我压缩文件这里用的是 archiver 模块
var fs = require('fs');
var archiver = require('archiver');
var output = fs.createWriteStream(__dirname + '/example.docx');
var archive = archiver('zip', {
zlib: { level: 9 } // Sets the compression level.
});
output.on('close', function() {
console.log(archive.pointer() + ' total bytes');
console.log('archiver has been finalized and the output file descriptor has closed.');
});
output.on('end', function() {
console.log('Data has been drained');
});
archive.on('warning', function(err) {
if (err.code === 'ENOENT') {
// log warning
} else {
// throw error
throw err;
}
});
archive.on('error', function(err) {
throw err;
});
archive.pipe(output);
archive.directory(__dirname + '/test/', false);
archive.finalize();好的,这样我们就吧处理好的文档输出到 example.docx 里了,用 Docx 软件打开看看吧
